使用 Navicat for MySQL 执行 SQL 语句时,出现 out of memory 问题的解决方法
本文共 256 字,大约阅读时间需要 1 分钟。
如果直接使用 Navicat for MySQL 的 “查询” 页签,执行很长内容的 SQL 语句(比如导入整个数据库的 SQL)时,就会出现 out of memory。

1 分析
原因很明显,因为导入整个数据库的 SQL 语句非常的长,几十万条记录的规模大概是 100 M 左右。所以要用其它方法来导入这些 SQL 语句。
2 解决
左侧列表右键选择要导入的数据库 -》运行 SQL 文件 -》选择要执行的 SQL 文件,然后 “开始”:
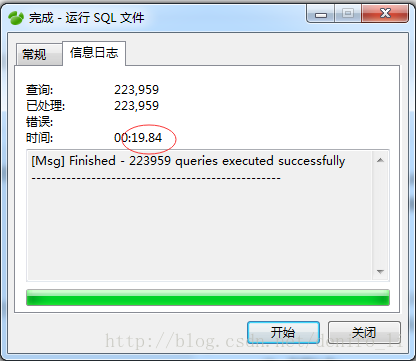
这种导入方法比直接一条一条地执行 SQL 语句快得多O(∩_∩)O~
你可能感兴趣的文章
状态压缩DP --> POJ 3254 Corn Fields
查看>>
TensorFlow 2.0 安装步骤
查看>>
图的深度优先遍历
查看>>
图的广度优先遍历
查看>>
递归方法输出x行y列字符串z
查看>>
桶排序-->改编自《啊哈!算法》
查看>>
冒泡排序-->改编自《啊哈!算法》
查看>>
快速排序-->改编自《啊哈!算法》
查看>>
利用队列解密QQ号码(三种方法)-->改编自《啊哈!算法》
查看>>
数位DP-->不降数
查看>>
数位DP需要用到的STL vector知识点
查看>>
“数位DP-->不降数”的初始化部分执行结果
查看>>
利用单链表实现逆序输出
查看>>
数位DP-->不要62
查看>>
利用STL中的vector实现“树”
查看>>
ASCII码对照表及“字符转数字”应用
查看>>
拆分自然数(dfs & STL)
查看>>
用pair做优先队列priority_queue元素的例子
查看>>
堆优化的Dijkstra算法(邻接表+优先队列+pair)
查看>>
Dijkstra算法-->改编自《啊哈!算法》
查看>>